
No SQL databases are an alternative for SQL databases, for many years SQL databases (relational databases) have been a key piece of the architecture of many applications and platforms. However, there are some use cases where SQL/relational databases don’t fit very well, for example: BigData, data that should no be consistent but requires high availability, and some other scenarios, NoSQL databases came to the rescue.
There are a bunch of NoSQL databases, each one with different behaviours and capacities. The only thing they have in common is that they are not the usual SQL/relational database.
For many years, in the Java world, we have been using the JPA (Java Persistence API) and JDBC as the standard to connect to SQL databases, and some people has tried to adapt those specifications for No-SQL databases, using for example JPA with a Mongo database. However, the principles for NoSQL database are very different than relation databases, therefore all those attempts usually ends in unsatisfactories results.
On the other hand, developers that want to integrate a NoSQL database should use a third party libraries, different from each other, without following and standarization. That means if you a Java developers needs to connect 4 NoSQL database, you have to use 4 different ways to do it.
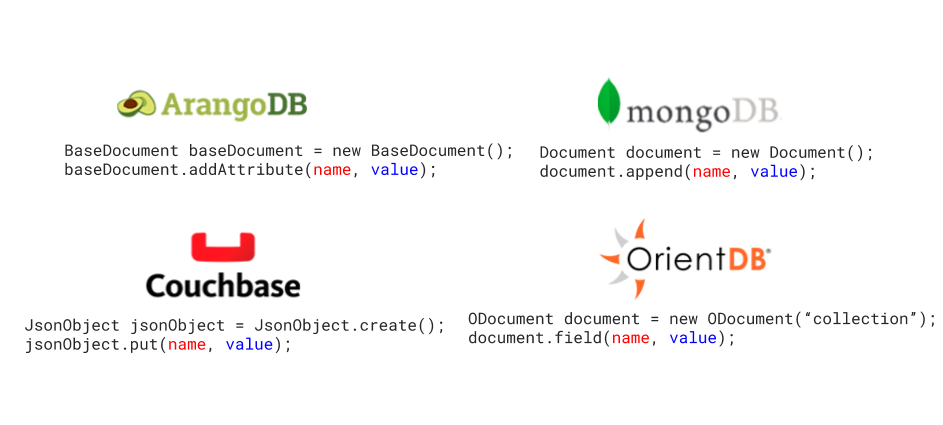
For the sake of standarization, Jakarta No SQL has arised as the new specification for working with NoSQL databases. A completely new set of modules and libraries, similar to JPA and JDBC but separate for them, based on the principles and particularities of the NoSQL databases.
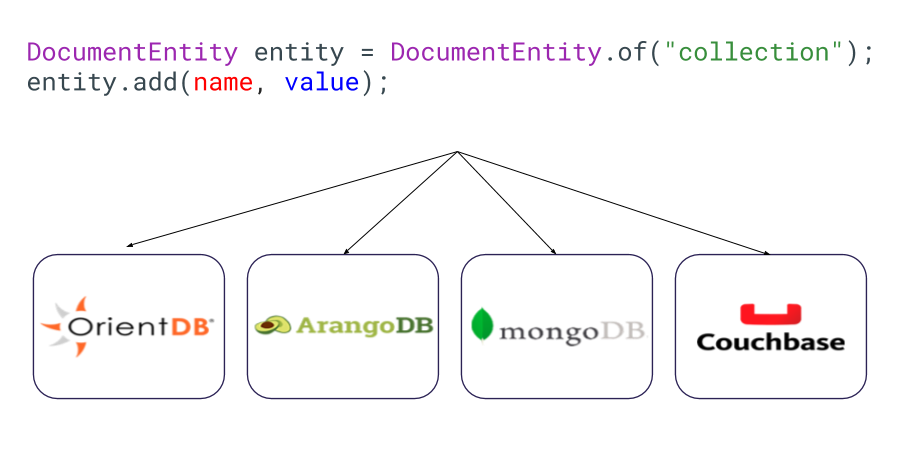
Types of NoSQL Databases
There are four popular NoSQL database types:
- Key-Value Databases
- Document Databases
- Wide-Column Databases
- Graph Databases
Diversity matters in the NoSQL World
As we have seen, there are different type of NoSQL database(I recommend this article to know more about them), and on each type we have several engines with its owns particularities, and mapping all those behaviors is a fundamental principal in this API. That’s why the standard is divided in the following pieces.
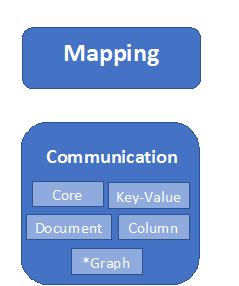
So, the Communication layers is the “low level” API, something similar to the JDBC api, but it has been divided in 5 modules, one of the is the core code, and then one module per NoSQL database type. The advantage of that is that the implementators of a NoSQL database only have to use the core library and implement the module for its NoSQL type, and forget any other features or behaviour of other family types.
The Graph, is an special case, because the reference implementation is based on Apache TinkerPop. So, that implementation can work for most of the cases.
Then we have the Mapping layer which is equivalent to JPA, providing annotations to create “entities” and map its columns. It’s very straight forward, we don’t have relationships like in JPA, but it’s very similar, so if you already know JPA, learning the NoSQL Mapping will be a piece of cake.
In addition to that, this layer provides CDI support, BeanValidation, and Repository pattern (springdata-like), which will simplify the effort and maximize the productive in our applications.
Let’s see an example
Entity
First we need to map our entity in a Java class.
import jakarta.nosql.mapping.Column;
import jakarta.nosql.mapping.Entity;
import jakarta.nosql.mapping.Id;
import java.io.Serializable;
import java.util.Objects;
import java.util.Set;
@Entity
public class Person implements Serializable {
@Id
private String name;
@Column
private Integer age;
@Column
private Set<String> telephones;
//Constructors, getters, setters, equals, hash, toString
}We can use the following annotations:
- @Entity
- @Id
- @Column
- @MappedSuperclass
- @Embeddable
- @Converts
And because it has BeanValidation support, we can use also any other annotation from it.
- @Max
- @Min
- @NotNull
- @Size
- etc
Repository
A repository is an interfaces that implements a CRUD method for us, and allows to create find and delete operations by only following some conventions while naming the methods. Just like SpringData or DeltaSpike Data repositories.
import jakarta.nosql.mapping.Page;
import jakarta.nosql.mapping.Pagination;
import jakarta.nosql.mapping.Repository;
import java.util.stream.Stream;
public interface PersonRepository extends Repository<Person, String> {
Stream<Person> findAll();
Page<Person> findAll(Pagination pagination);
Stream<Person> findByTelephonesIn(String telephones);
Stream<Person> findByAgeGreaterThan(Integer age);
Stream<Person> findByAgeLessThan(Integer age);
}We can also create our custome queries using the @Query annotation.
Producers
Now the question is, how that the Repository knows which database to use, and how to connect to it. We need to create a Producer for the Manager of the database, we have 4 Manager types (KeyValue, Document, Column and Graph).
The Manager (any of the four mentioned before) is the equivalent of the EntityManager in JPA. There are many ways to create one (like in JPA) but I prefer to use the following approach.
import jakarta.nosql.document.DocumentCollectionManager;
import org.eclipse.microprofile.config.inject.ConfigProperty;
import javax.enterprise.context.ApplicationScoped;
import javax.enterprise.inject.Disposes;
import javax.enterprise.inject.Produces;
import javax.inject.Inject;
@ApplicationScoped
class DocumentManagerProducer {
@Inject
@ConfigProperty(name = "document")
private DocumentCollectionManager manager;
@Produces
public DocumentCollectionManager getManager() {
return manager;
}
public void destroy(@Disposes DocumentCollectionManager manager) {
manager.close();
}
}And the declare the configuration in the microprofile-config.properties file with the details of the connection, host, provider, database, etc. The configuration will depend on the database type and provider.
document=document document.database=demo document.settings.jakarta.nosql.host=192.168.99.100:27017 document.provider=org.eclipse.jnosql.diana.mongodb.document.MongoDBDocumentConfiguration
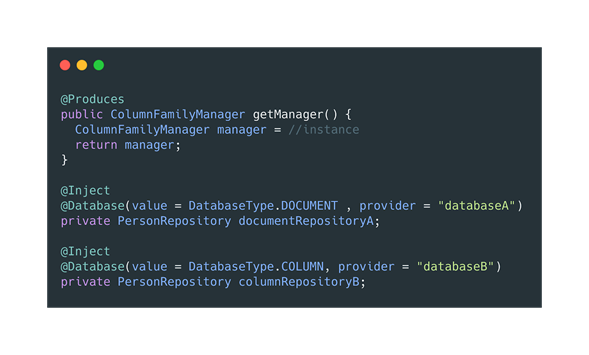
If for some reason, we have more than one NoSQL database in our application, and we create more than one Producer, we will need to use the @Database annotation.
What else is there?
There is more in Jakarta NoSQL, for example the Fluent API, more similar to the JDBC statements, where you can create customize queries and operations. It provides Templates for each NoSQL type and methods to make a CRUD.
But at least for now, this article covers the most common use case I can imagine we will have to implement in our applications.
References
- https://phoenixnap.com/kb/nosql-database-types
- http://www.jnosql.org/spec/
- https://dzone.com/articles/whats-new-with-jakarta-nosql-part-i-introduction-t
- https://github.com/AdamGamboa/jakarta-nosql-demo/