
Las bases de datos NO SQL son una alternativa para las bases de datos relacionales (SQL) que usualmente conocemos, por muchos años las bases de datos relacionales han sido una pieza importante de la arquitectura de muchas aplicaciones y plataformas. Sin embargo, existen muchos casos de uso donde las bases de datos SQL/relacionales no calzan muy bien, por ejemplo:: BigData, datos que no deben ser consistentes pero requiren de alta disponibilidad, así como otros escenarios, para ello las bases de datos NoSQL databases llegaron al rescate.
Hay una gran cantidad de bases de datos NoSQL, cada una de ellas con sus sus diferentes comportamientos y capacidades. La única cosas que ellas tienen en común es que no son relacionales.
Por muchos años, en el mundo de Java hemos estado usando JPA (Java Persistence API) y JDBC como los estándares para conectar a bases de datos SQL, algunas personas han intentado adaptar estas especificaciones para las bases de datos NO-SQL, usando por ejemplo JPA con MongoDB. Sin embargo, los principios y bases para las bases de datos NoSQL son muy diferentes a los principios en bases de datos relaciones, por lo tantos todos esos intentos usualmente terminan con resultados insatifastorios.
Por otro lado, los desarrolladores que quieren interar una base de datos NoSQL debe de utilizar una librería de terceros, diferente para cada tipo de base de datos, sin seguir un estándar. Eso significa que si un desarrollador Java necesita conectarse a 4 diferentes motores de bases de datos NoSQL, tendrá que aprender y aplicar 4 formas diferentes de hacerlo.
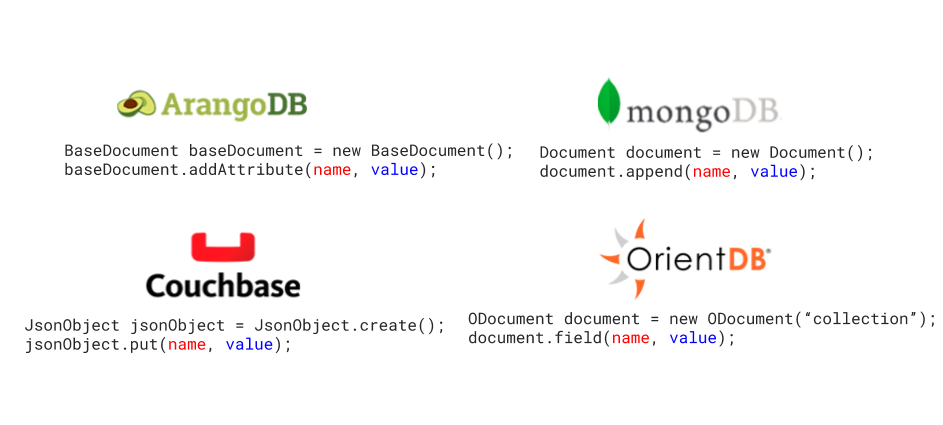
En aras the la estandarización, Jakarta No SQL se ha levantado como la nueva especificación para trabajar con bases de datos NoSQL. Un nuevo set de módulos y librerías, simiar a JPA y JDBC pero independientes de ellos, basado en los principios y particularidades natos de las bases de datos NoSQL.
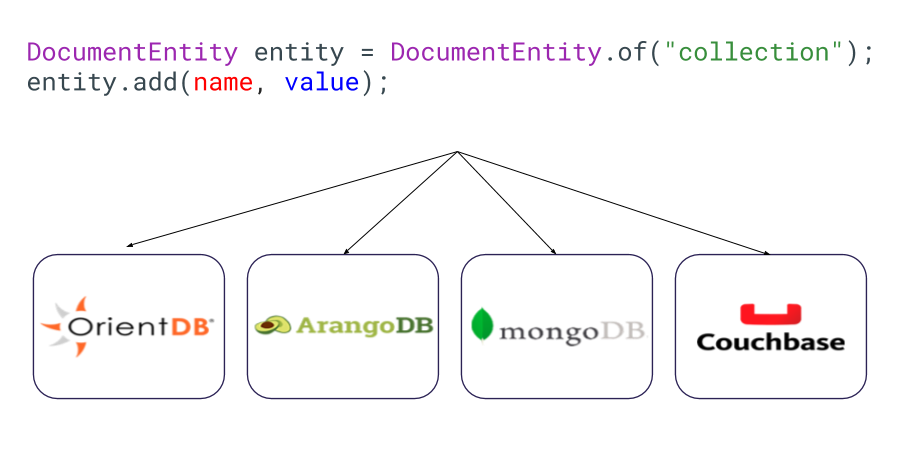
Tipos de bases de datos NoSQL
Hay cuatro tipos de bases de datos NoSQL:
- Key-Value Databases
- Document Databases
- Wide-Column Databases
- Graph Databases
La diversidad importa en el mundo NoSQL
Tal como hemos visto, hay diferentes tipos de bases de datos NoSQL (Recomiendo este artículo para conocer más sobre ellos), y cada tipo de base de datos tiene muchos motores de base de datos con sus propias particularidades, y mapear todas esas conductas es una parte fundamentar de este API. Esta es la razón por que el estandar Jakarta NoSQL se encuentra dividido en las siguientes partes.
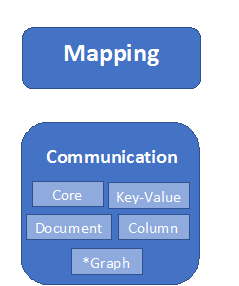
Entonces, la capa de Comunicación es el API de “bajo nivel”, algo similar al API de JDBC, pero se encuentra dividido en 5 módulos, uno de ellos es código base (core) y los otros corresponde a un módulo por tipo de base de datos NoSQL. La ventaja de esto, es que los implementadores de bases de datos NoSQL solo tiene que usar la librería core e implementar el módulo para su tipo de base de datos, de esta manera olvidarse o prescindir de caracteristicas que corresponden a otros tipos de bases de datos.
El tipo Grafo (Graph), es un caso especial, porque la implementación de referencia está basada en Apache TinkerPop. Debido a que esa implemenatación funciona para la mayoría de los casos (para que reinventar la rueda, verdad?).
Luego tenemos la capa de Mapping, la cual es el equivalente a JPA, proporcionado anotaciones para crear “entidades” y mapear sus columnas.. Es bastant sencillo, no tenemos relaciones como en JPA, pero sigue siendo muy similar a JPA, así que si ya lo conoces, aprender el mapeo de NoSQL será muy muy muy sencillo.
Además, esta capa tiene soporte con CDBI, BeanValidation y el patrón Repositorio (como spring data), el cual simplificará el esfuerzo y maximizará la productividad en nuestras aplicaciones.
Veamos un ejemplo
Entity
Lo primero que demos hacer es mapear nuestra entidad en una clase de Java.
import jakarta.nosql.mapping.Column;
import jakarta.nosql.mapping.Entity;
import jakarta.nosql.mapping.Id;
import java.io.Serializable;
import java.util.Objects;
import java.util.Set;
@Entity
public class Person implements Serializable {
@Id
private String name;
@Column
private Integer age;
@Column
private Set<String> telephones;
//Constructors, getters, setters, equals, hash, toString
}Podemos usar las siguientes anotaciones:
- @Entity
- @Id
- @Column
- @MappedSuperclass
- @Embeddable
- @Converts
Y debido a que tiene soporte para BeanValidation, también podemos utilizar cualquiera de sus anotaciones.
- @Max
- @Min
- @NotNull
- @Size
- etc
Repository
Un repositorio es una interface que implementa los métodos de CRUD por nosotros, y nos permite create métodos para las consultas de consulta y eliminación siguiendo una convención en el nombre y declaración de los métodos. Muy similar a los repositorios de SpringData oDeltaSpike Data.
import jakarta.nosql.mapping.Page;
import jakarta.nosql.mapping.Pagination;
import jakarta.nosql.mapping.Repository;
import java.util.stream.Stream;
public interface PersonRepository extends Repository<Person, String> {
Stream<Person> findAll();
Page<Person> findAll(Pagination pagination);
Stream<Person> findByTelephonesIn(String telephones);
Stream<Person> findByAgeGreaterThan(Integer age);
Stream<Person> findByAgeLessThan(Integer age);
}También podemos crear nuestro propios queries personalizados, para aquellos casos donde no es posible realizarlo por medio de la convención del nombre del métodos, utilizando la anotación @Query.
Productores
Ahora la pregunta es, ¿Cómo es que el repositorio conoce que base de datos utilizar, y como conectarse a ella? Tenemos que crear un Producer para el Manager de la base de datos, tenemos 4 tipos de Manager (KeyValue, Document, Column and Graph).
El manager (cualquiera de los 4 mencionados anteriormente) es el equivalinete al EntityManager en JPA. De igual manera a JPA hay muchas maneras de crear un Manager, pero en lo particular prefiero la siguiente manera.
import jakarta.nosql.document.DocumentCollectionManager;
import org.eclipse.microprofile.config.inject.ConfigProperty;
import javax.enterprise.context.ApplicationScoped;
import javax.enterprise.inject.Disposes;
import javax.enterprise.inject.Produces;
import javax.inject.Inject;
@ApplicationScoped
class DocumentManagerProducer {
@Inject
@ConfigProperty(name = "document")
private DocumentCollectionManager manager;
@Produces
public DocumentCollectionManager getManager() {
return manager;
}
public void destroy(@Disposes DocumentCollectionManager manager) {
manager.close();
}
}Y luego declaro la configuración en el archivo microprofile-config.properties con los detalles de la conexión, host, provider, base de datos, etc. La configuración dependerá del tipo de base de datos y su proveedor.
document=document document.database=demo document.settings.jakarta.nosql.host=192.168.99.100:27017 document.provider=org.eclipse.jnosql.diana.mongodb.document.MongoDBDocumentConfiguration
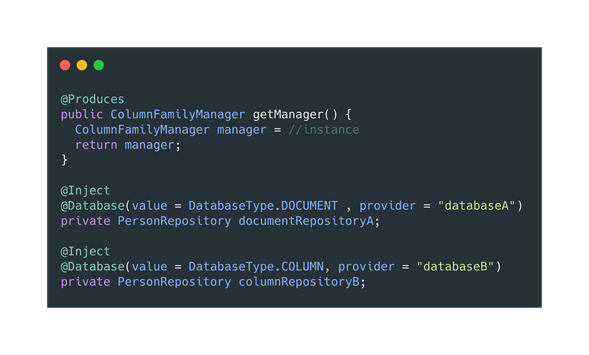
Si por alguna razón, tenemos más de una base de datos NoSQL en nuestra aplicación, y creamos más de un Producer, necesitaremos usar la anotación @Database.
Que más hay?
Hay mucho más en Jakarta NoSQL, por ejemplo el API Fluido (Fluent API), mas similar a los statements de JDBC, donde se puede crear queries personlizados y operaciones según las necesidades especificas aun nivel más bajo. Este provee Templates (plantillas) para cada tipo de NoSQL y permite las operaciones CRUD.
Peron al menos a este momento, este artículo cubre los casos de uso más comunes que puedo imaginar llegamos a implementar en nuestas aplicationes.
Referencias
- https://phoenixnap.com/kb/nosql-database-types
- http://www.jnosql.org/spec/
- https://dzone.com/articles/whats-new-with-jakarta-nosql-part-i-introduction-t
- https://github.com/AdamGamboa/jakarta-nosql-demo/